From Vanilla Transformers to Modern LLMs: What Changed After the Original Transformer (Part 2)
Modern LLM Architecture (Part 2): Efficient Attention and Long Context

This post is Part 2 of a 3-part series on modern LLM architectures. Each part can be read independently.
Part 1 talks about the techniques for improving the training stability of LLMs.
Part 3 talks about low-level hardware attention optimizations and MuonClip Optimizer
Attention Optimizations
There are 2 types of Attention Optimization: Architectural Level and Low-level Hardware
A. Architecture Level Optimization:
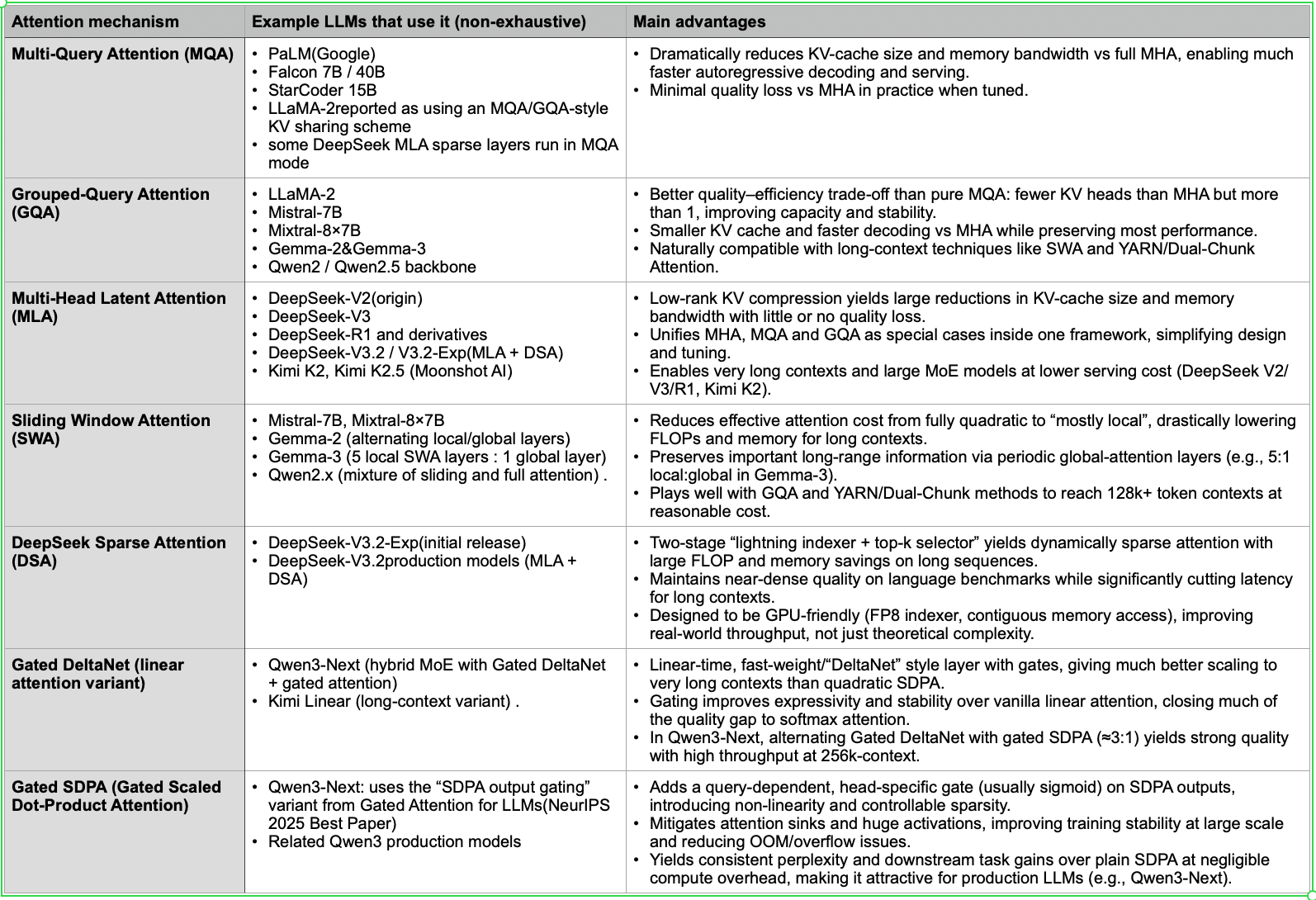
Multi-Query Attention (MQA)
Grouped-Query Attention (GQA)
Multi-head Latent Attention (MLA)
Sliding Window Attention (SWA)
DeepSeek Sparse Attention (DSA)
Gated DeltaNet (a variation of Linear Attention)
Gated SDPA Attention
These primarily reduce KV-cache memory and compute cost.
B. Low-level Hardware Optimization:
FlashAttention
Ring Attention
Stripe Attention
PagedAttention (vLLM)
RadixAttention (SGLang)
These primarily improve the inference efficiency and apply at the inference and serving levels.
We will first talk about Architectural-Level Optimizations in this post:
A1) Multi-Query Attention (MQA)
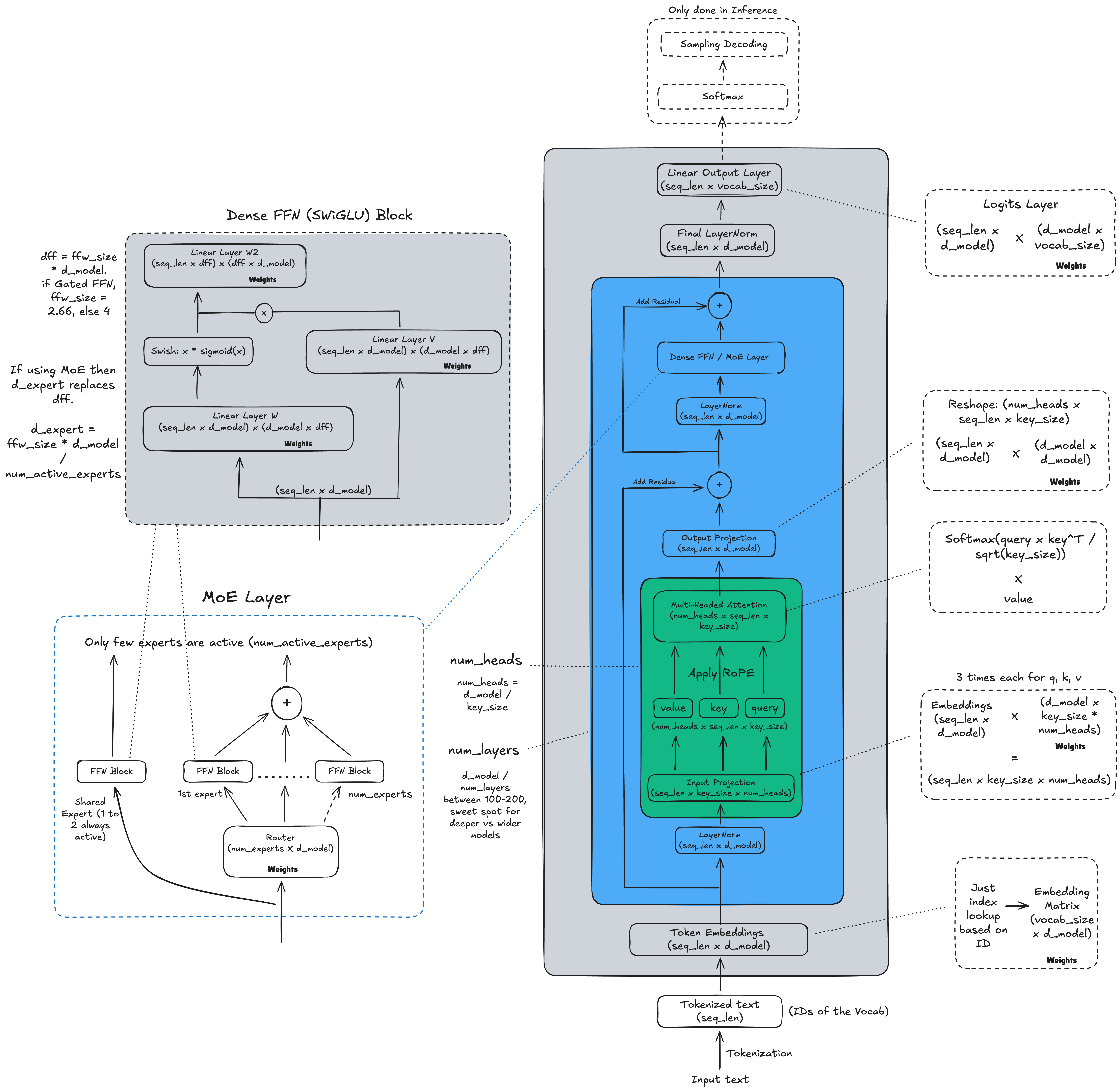
In the Multi-Headed Attention (MHA), each query head attends to its own set of key and value heads, as shown in the figure below. However, this significantly increases the model parameters as well as the KV cache, which will reduce the throughput during inference.
To solve this issue, Multi-Query Attention was introduced, which is as follows:
All the query heads share the same key and value heads, which drastically reduces the KV-cache memory. However, this comes at a price as it cuts the model parameters and reduces the quality and the potential capacity to learn.
A2) Grouped-Query Attention (GQA)
This is the middle ground between MHA and MQA. With GQA we split query heads into groups of size, each with its own keys and values. The choice is a trade-off between memory savings and potential accuracy loss. A larger group size will result in more memory savings but may also lead to a larger approximation error in the attention computations.
In practice, the optimal group size may need to be determined empirically based on the specific model architecture and the trade-off between memory efficiency and model performance.
A3) Multi-head Latent Attention (MLA)
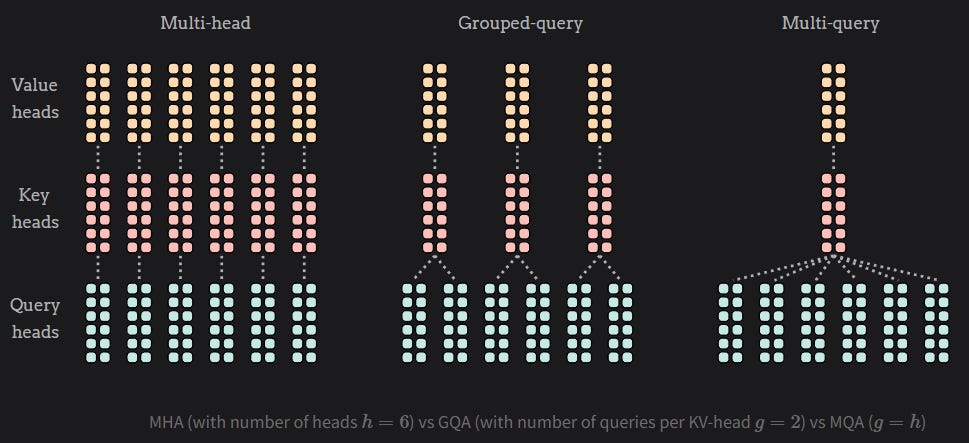
Here, the author proposed to use a compressed latent vector for query, key, and values.
MLA compresses K and V into a latent representation stored in the KV cache, dramatically reducing memory usage. This significantly reduces the memory requirement at inference and also the activation memory during pre-training.
Queries are also low-rank compressed during training to reduce activation memory.
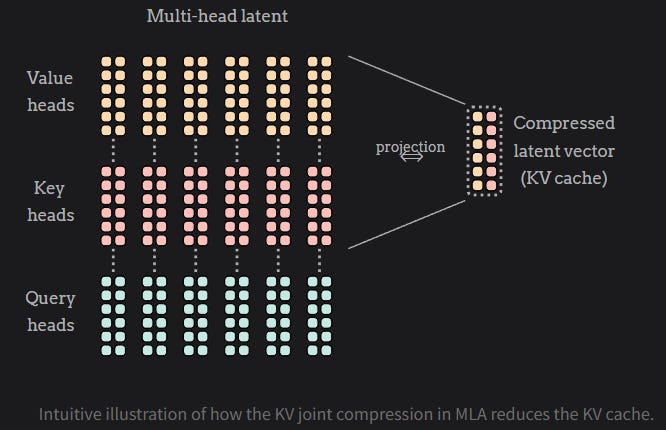
DeepSeek-V2 results show better performance than MHA with significantly lower KV cache per token.
However, with MLA, we can’t directly apply the RoPE (discussed in Part 1), since it is incompatible with low-rank KV compression. Additionally, it doesn’t allow the weight absorption of K and V weights during inference.
Hence, we split both Q and K into 2 parts. The first part is compressed, and the other part is uncompressed, where the RoPE is applied.
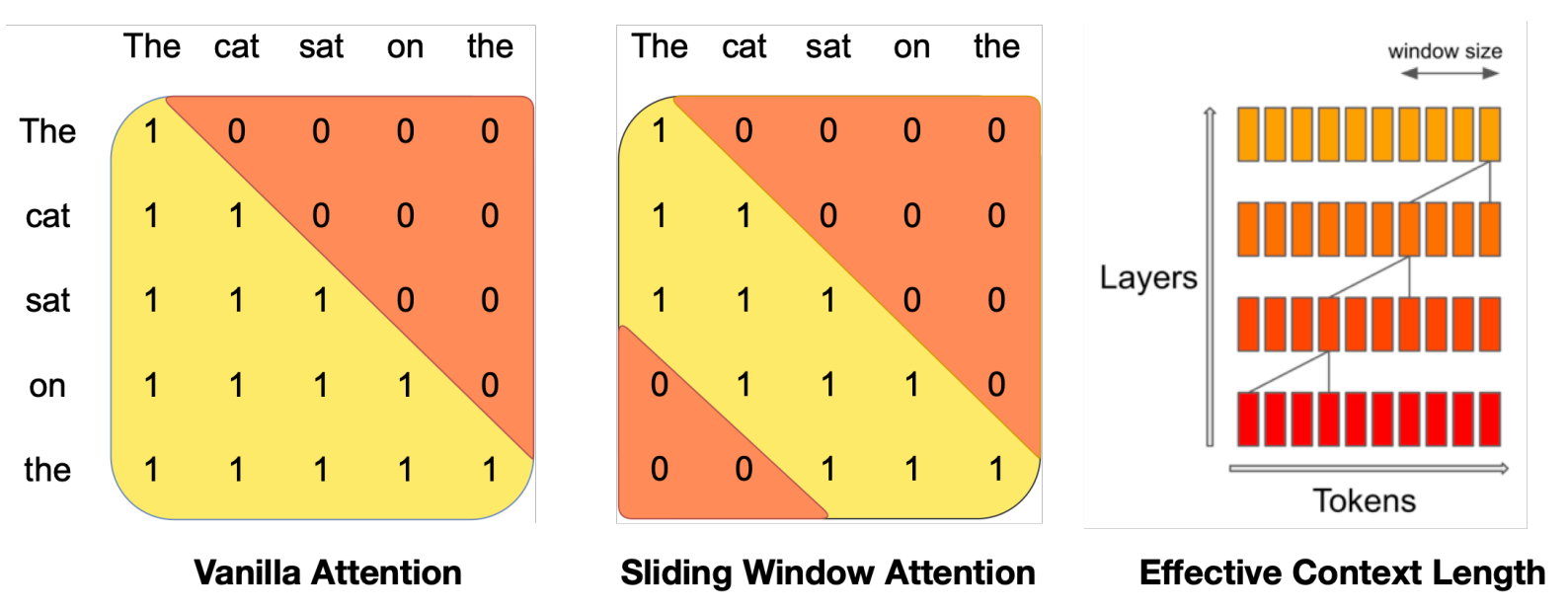
A4) Sliding Window Attention (SWA)
The number of operations in vanilla attention is quadratic in the sequence length, and memory increases linearly with the number of tokens. At inference time, this incurs higher latency and smaller throughput due to reduced cache availability. To alleviate this issue, instead of attending to all the previous tokens in the attention computation, we only attend to the tokens that fall in the window size that we choose (ex. W = 3 in the figure below)
A5) DeepSeek Sparse Attention (DSA)
This is another variant of attention that reduces the attention span of the query token, which improves the efficiency. As seen previously, in Vanilla Attention, each query has access to all the past tokens to attend to for the calculation of the attention score. Sliding Window Attention improves upon this a bit, where each query can only attend to the previous tokens for some window size that we have decided.
Whereas, in DeepSeek Sparse Attention (DSA), instead of a fixed window size, we can attend to the top-k past tokens at any position. This way it creates a sparsity in the Attention Mask as shown in the figure below (where, top-k = 3)
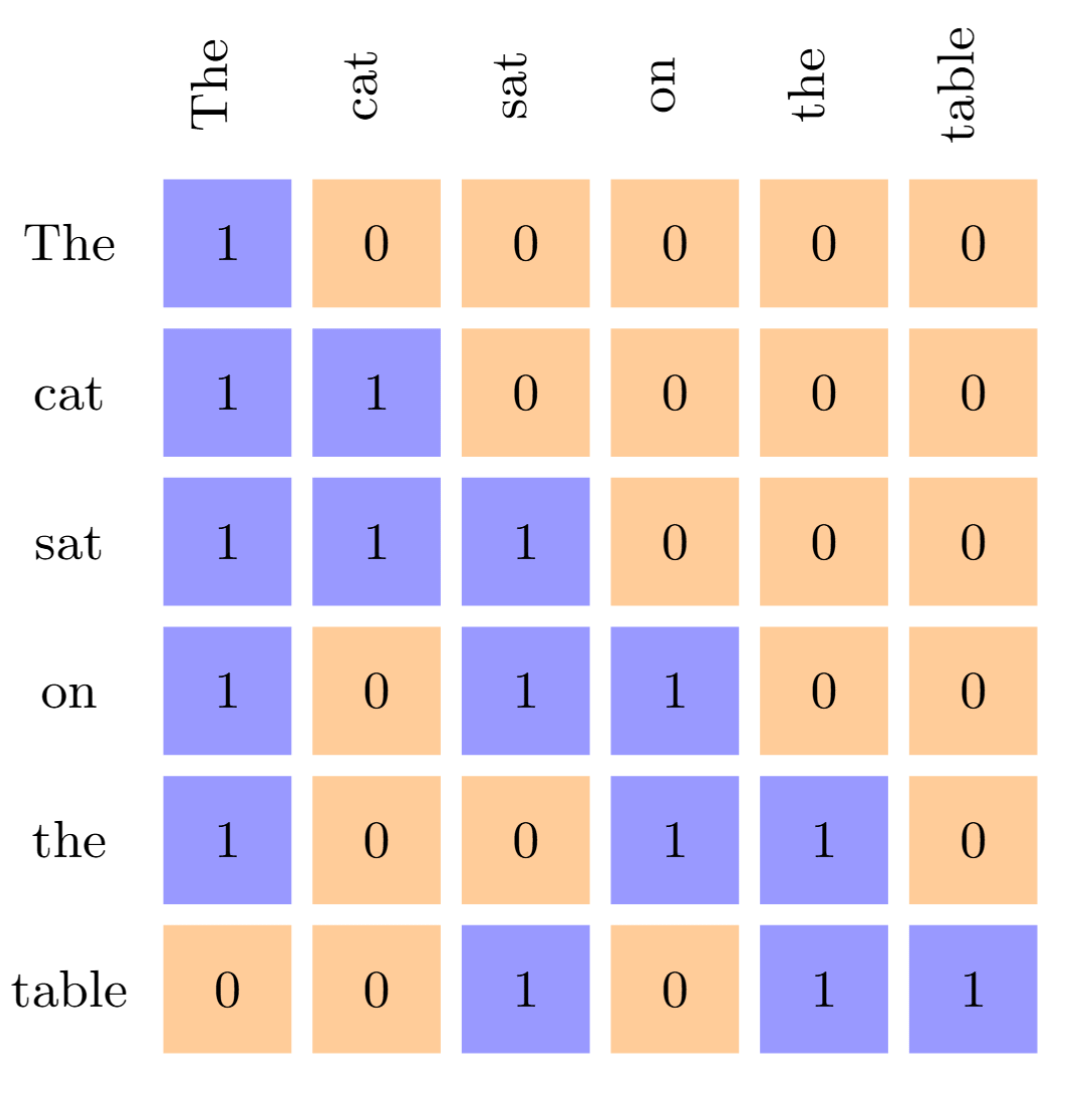
DSA consists of 2 components to achieve this: a lightning indexer, a fine-grained token selection mechanism
Lightning Indexer: it computes the index score for all the past tokens (i.e., score I for the token that is at the index s)
\(\displaylines { I_{t, s} = \sum_{j=1}^{H^I} w_{t, j}^I . ReLU(q_{t, j}^I . k_s^I) \\ \\ Where, \\ I_{t,s} = \text{score of the token at position s for the current query token t} \\ H^I = \text{total number of indexer heads (64 for DeepSeek-V3.2-Exp} \\ w_{t, j}^I = \text{learned per-indexer heads weighting coefficient} \\ q_{t, j}^I = \text{query vector for current token t in indexer head j} \\ k_s^I = \text{key vector for the token at position s} }\)Token Selector: It selects the top-k tokens with the high index scores. This is a hyperparameter that is set as top-k = 2048 in DeepSeek-V3.2-Exp. After that, it creates a Sparse Attention Mask that masks out the tokens that are not selected, in addition to the future tokens, of course.
A6) Gated DeltaNet (Linear Attention)
Gated Delta Net is another variation of Linear Attention; the main advantage of this is that it linearly depends on sequence length instead of quadratic dependence in the case of scaled-dot-product-attention.
The query and key weights go through 1D convolution, SiLU activation and then L2 norm. The value weights go through 1D convolution and SiLU activation. Alpha and Beta weights also go through Sigmoid/SiLU/Softplus activation. The final output is generated based on the Gated Delta Rule as explained below.
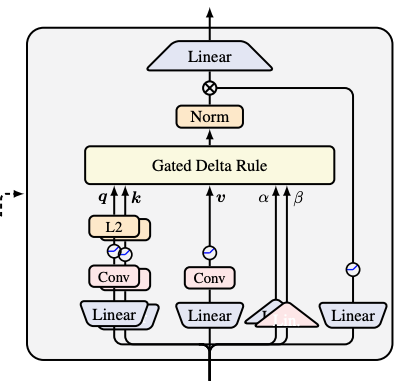
This output again goes through normalization and finally through another gate that is created by a Sigmoid activation on the linear weights.
A7) Gated SDPA (Scaled-Dot-Product-Attention)
In Gated Attention, the gating is applied after the Attention computation, as shown in the figure, which is the most effective gating based on the MMLU, Perplexity and Loss scores.
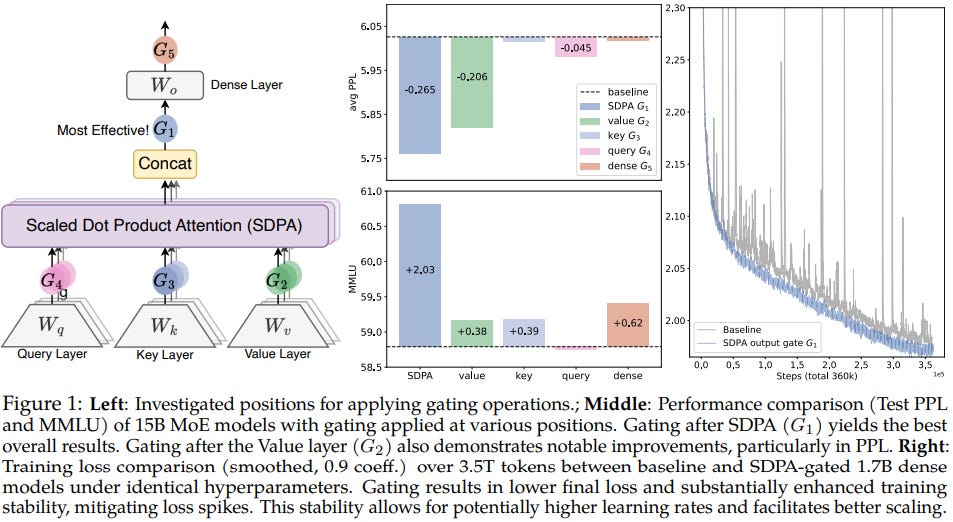
Advantages of Gated Attention:
1. Improved Training Stability and Scaling
Reduced Training Instability: Gating prevents “massive activations” (exploding values in the hidden states), resulting in significantly smoother training loss and almost entirely eliminating loss spikes.
Higher Learning Rates: Because the training is more stable, gated models can tolerate higher learning rates, enabling faster and more effective training without diverging.
Improved Scaling Properties: Gated attention enhances the model’s ability to scale to larger sizes and more parameters without increased instability.
2. Elimination of “Attention Sinks”
Prevents Attention to Initial Tokens: Standard transformers often suffer from the “attention sink” phenomenon, where a high percentage of attention (often >40%) is wrongly directed to the first token. Gated attention effectively reduces this focus on the first token to under 5%, allowing the model to focus on more relevant information.
Better Long-Context Extrapolation: By eliminating attention sinks, gated models demonstrate superior performance in long-context scenarios, such as 128k context windows, often achieving significantly better scores on RULER benchmarks compared to standard models.
3. Increased Model Performance
Higher Accuracy: Gated attention consistently improves performance on downstream tasks, with up to 2% improvement on benchmarks like MMLU and 0.2 lower perplexity.
Increased Expressiveness: By introducing non-linearity between the value and output projections, it boosts the model’s ability to represent complex relationships.
4. High Efficiency
Low Computational Overhead: Adding this gating mechanism is extremely lightweight, introducing less than 2% additional latency, making it highly efficient.
Quantization Friendly: By suppressing extreme activation values, gated models are easier to compress and quantize without significant loss of accuracy.
Gated SPDA Attention is often used with Gated DeltaNet in a Hybrid scheme with a 3:1 or 5:1 ratio of layers. 3 Gated DeltaNet Layers and 1 Gated SPDA, and so on. The implementation of this hybrid is in Qwen3 Next 80B-A3B
Summary:
References:
That’s it for this post. Next Part-3 will drop soon, so stay tuned!!
Quick Part-3 Teaser: MoE, KV Cache Reduction, Muon Optimizer
Content:
FlashAttention (1–4)
Ring / Stripe Attention
PagedAttention (vLLM)
RadixAttention (SGLang)
MoE
MuonClip Optimizer